A driving factor of virtualization in the old days was the immediate efficiencies that were realized with each P2V. It was money in the bank each time consolidation ratios increased and fewer physical boxes were required. In the physical world, we tried to ensure each OS and associated app(s) had plenty of excess CPU, memory, and storage resources available to it…just in case they were needed at some point in the future. The target utilization rate was typically under 20% (often less than half that) and a sustained rate above that was a cause for concern. In contrast, virtualization aspired resource utilization rates of 60-80% per host and a little below that cluster-wide. While high utilization became the new norm, over-provisioning of resources was typically avoided (at least in production).
Fast forward to the cloud era (private / public, doesn’t matter), where over-provisioning of machines consuming shared resources is a necessary evil for driving efficiencies at every level of infrastructure and scale. This is especially true for infrastructure-as-a-service. This evil is also one of the benefits…it’s what helps deliver the perception of unlimited resources to the consumer without actually making that kind of investment. While the cost of spare capacity has become less of an issue over time, over-provisioning of resources remains a common practice for many small shops, enterprises, and service providers alike.
This is possible due to the fact that resource allocation does not necessarily equal resource consumption. I don’t think I need to get into the nitty-gritty details of why that’s the case — this is virtualization 101, folks — but in the general sense, allocated resources that are unused are available for other VMs to consume (many ways that rule can break, but we’re speaking in general terms here). This is especially true for storage capacity, considering storage allocation per machine is often significantly greater than what will actually be consumed. Thin provisioning (docs | kb) largely addresses this issue, but more on that later. The remainder of this post will focus on storage capacity.
Allocated vs. Used Capacity
Allocated storage is just that — the total storage capacity that is allocated to virtual disks (VMDK’s), datastores, etc. This represents the total allotment of capacity available for use by the operating system and apps within a VM and, from a datastore perspective, the total aggregate capacity available for storing all virtual machine data. Without thin provisioning (aka thick provisioning), the full VMDK allocation (e.g. 100GB) is subtracted from the datastore’s available capacity. In contrast, when the disk is thin provisioned only the used/written data (e.g. 20GB) is subtracted from the datastore’s capacity even as the OS recognizes the entire allocation as available capacity.
This means that, technically, you should be able to provision roughly 20 VM’s with 100GB thin-provisioned disks on a single 1TB datastore…assuming less than 1/2 of each disk contains data. (20 x 50GB = 1TB, give or take). Sure this practice can be risky in cases where provisioned capacity of some or all machines expands beyond available capacity to fill free space, but it’s up to the provider to determine how to balance risk, scale, and efficiency (and SLA’s for that matter). There are best practices for avoiding such situation. Ideally, the provider uses vRealize Operations to gain the necessary insight and guidance for maintaining optimal efficiency while minimizing risk.
Another side effect of thin provisioning storage is it promotes oversizing of VM disks because, technically, there is no real datastore capacity penalty for doing so since the unused disk does not impact available datastore capacity. But things get tricky when cloud management tools are added to the mix. This is largely due to the cloud allocation and economical models these tools provide for aligning cloud service to business requirements. Consider costing practices, capacity guarantees, SLA’s, etc — these might vary between tenants or lifecycle stage. Other factors such as resource constraints, efficiency goals, and cost controls will also impact how resources are allocated (and thereby consumed).
The Cloud Allocation Model
Solutions like vCloud Director and vRealize Automation abstract available storage resources (vSphere datastores in this case) to align with the cloud consumption model…
- vCD aggregates system-wide [vSphere] resources using the Provider Virtual Datacenter (PvDC) construct and sub-allocates for tenant consumption via an Organizational Virtual Datacenter (OvDC).
- vRA aggregates endpoint resources into a cloud Fabric and sub-allocates to Business Groups using Reservations.
These concepts are very similarly structured and serve a common purpose, but there are some important differences in the allocation model that are worth spelling out (again, focusing on storage)…
- vCD: Storage capacity is allocated to an OvDC and consumed by machines at provisioning time. vCD supports thin provisioning and fast clones (aka linked clones) and calculates storage consumption based on actual used/written space. If an OvDC has 20GB of available capacity, I can still provision a machine with a 100GB disk as long as less than 20GB is used. Again, there are a lot of risks and caveats with this, but my point here is it’s technically possible.
- vRA: Storage capacity is allocated to a Reservation from any number of storage sources (datastores, aka storage paths). vRA supports thin provisioning (via custom property) and linked clones but validates the availability free storage capacity to cover the full disk allocation prior to provisioning. So if the target reservation has 20GB of available capacity remaining, a machine with a 100GB thin-provisioned disk will fail to provision even if the thin disk is less than 20GB. This is by design.
That last bullet is precisely why I wanted to write this post as this tidbit comes up all the time. vRA takes more of an enterprise approach to resource allocations to ensure resiliency. At provisioning time, workload placement is determined based on an algorithm that considers defined policies, status, priority and capacity (physical, free, reserved). Next we’ll explore the storage allocation logic and a quick-n-dirty workaround to get you on your way to over-provisioning your heart out.
Storage Allocation
Prior to provisioning any machine, vRA performs an “allocation” request to ensure the requested resources are available for consumption as dictated by the machine(s) in flight. If the allocation stage passes, the machine is provisioned as expected. If it fails…well, provisioning fails.
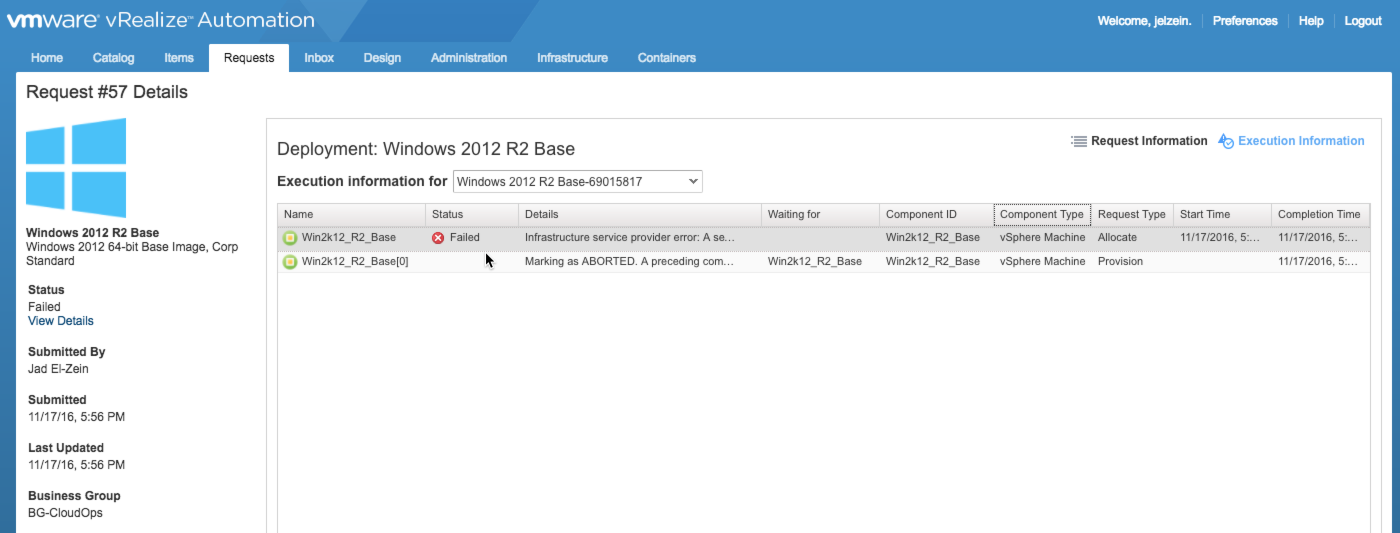
Lets assume the target Reservation is properly configured with a single available storage path and the machine requested is configured with thin-provisioned disks. vRA needs to consider available capacity to determine whether it can make a compliant allocation. There are actually 3 storage metrics that are considered in this calculation:
- Free – This is the total available physical capacity on the associated datastore as reported by the endpoint data collection
- This Reservation Reserved – This is the total storage allocation available for this reservation. The interesting thing here is the storage reservation can be much greater than what is physically available. Over-provisioning starts here. More on this in a bit.
- This Reservation Allocated – This is the sum of all allocated space from all machines/disks using this storage path.
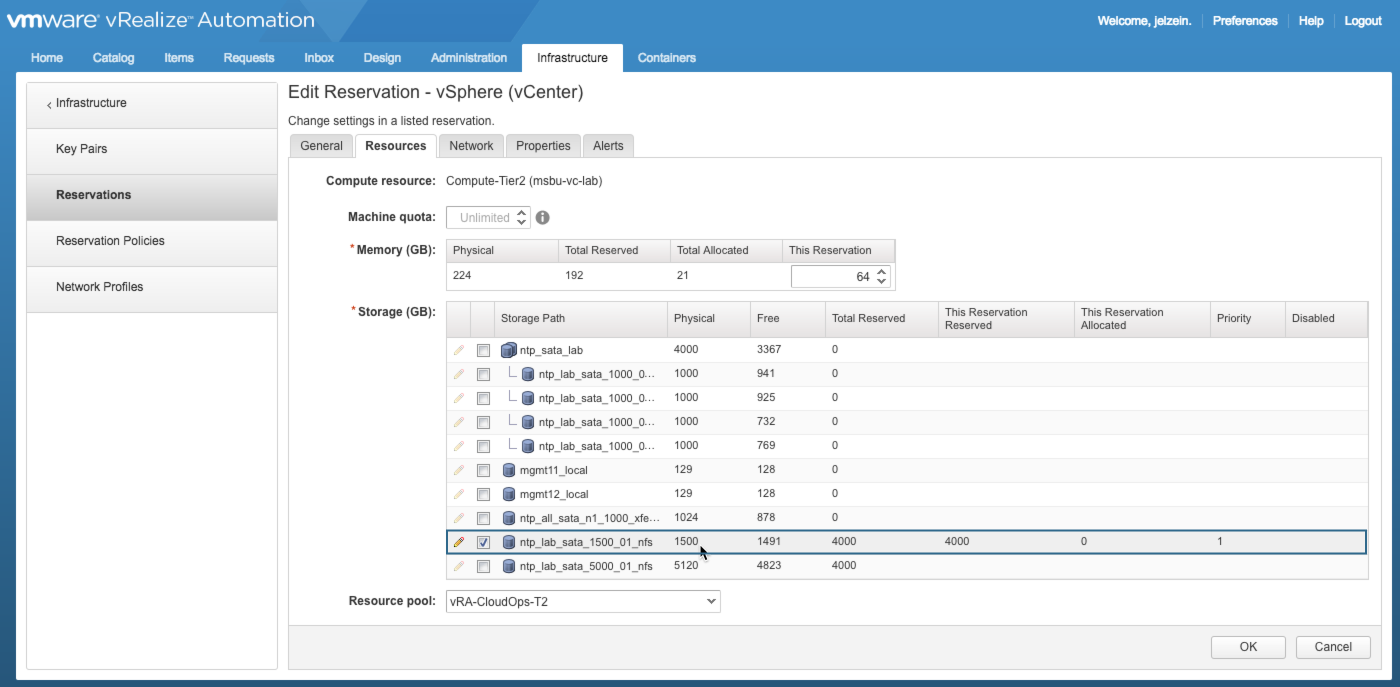
During this stage, the workflow considers the requested storage allocation for each component and compares that to the available storage capacity on the target storage path(s). (Note: available storage capacity = Reserved – Allocated). In this example, the selected storage path has 1491GB (of 1500GB) Free. But also notice 4000GB of storage has been reserved for use by this Reservation. And the only way to consume 4000GB of a 1500GB datastore is by doing it logically…i.e., over-provisioning. A machine’s allocated storage is measured against the Reserved capacity while used (written) storage is measured against Free capacity. Make sense?
Here’s a glimpse at the storage allocation process when a machine is requested…
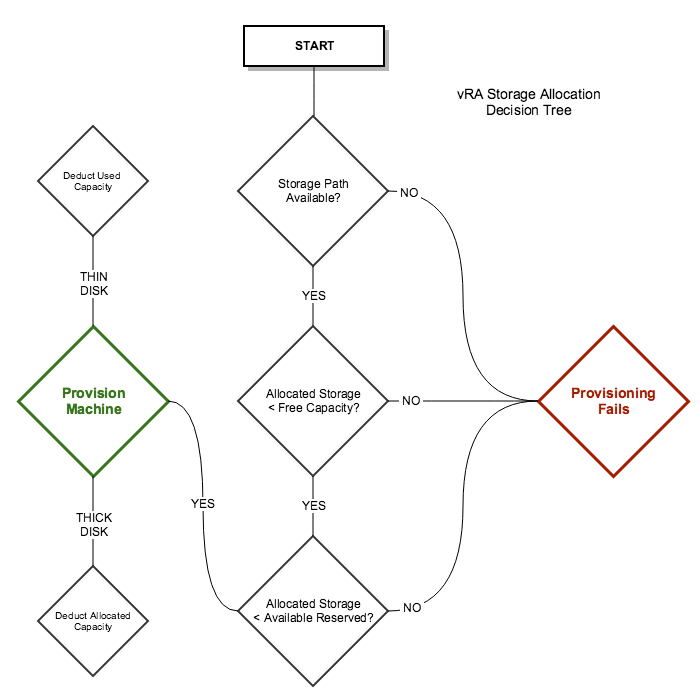
Note that there are several other decision factors that impact machine placement and allocation of resources…this diagram depicts only the storage allocation aspects within a specified Reservation. This diagram also assumes that only one storage path was available to start with. If others were available, vRA would first determine which one to use based on status, applicable storage policy, priority or available capacity. If all have equal weight, vRA will round-robin provisioning across storage paths.
Over-Provisioning Storage in vRA
Now that you have some idea of how storage allocations are determined, let’s take a look how you’d put over-provisioning to practice. Enabling over-provisioning is easy as long as you understand the caveats, limits, and risks. Here are some general guidelines for making this all work:
- Use dedicated datastore(s) for vRA as a best practice (i.e. not shared with standard vSphere or other external provisioning). This is especially critical when over-provisioning so vRA can keep track and manage storage capacity.
- Use thin-provisioned disks for all machines (details on enabling this below). Have a good understanding of the potential data growth within thin-provisioned disks throughout the machine’s lifecycle to ensure you don’t run into contention later.
- Set the Storage Reservation to something greater than the datastore’s physical capacity. This will depend on how conservative (1.5X) or aggressive (4X or higher) you plan to be.
- The allocated disk capacity cannot be greater than the Free capacity of the storage path (see decision flow above)…even if thin provisioning is enabled. Also note that the allocated capacity is the sum of all disks of a machine.
- Keep an eye on “This Reservation Allocated” — if that number is getting close to the Reserved capacity (meaning available capacity is low) and Free capacity is still plentiful, you can adjust the reservation to meet your needs…it will be effective immediately. This will be especially true if you’re using Linked Clones since those delta disks have minimal storage impact. You can set an Alert for storage capacity.
The screenshots and info below are example configurations for storage over-provisioning based on these guidelines…
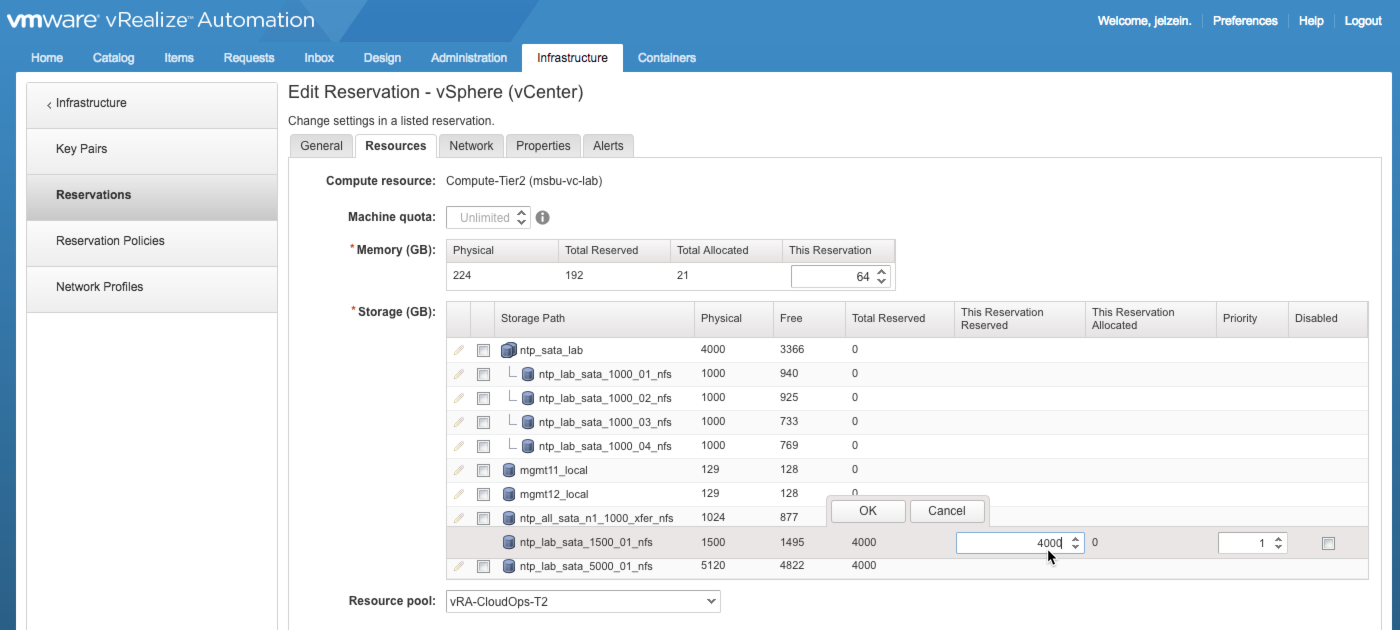
1) Attach a Storage Path and set the desired [over-provisioned] storage Reservation.
In this example, I have assigned an empty 1500GB storage path and reserved 4000GB for storage allocations. This is the first step for enabling over-provisioning. I should be able to go much higher based on my sizing habits, but this is a good start…adjustments can be made later.
2) Enable Thin Provisioning for target Blueprints
Thin Provisioning is enabled by adding the VirtualMachine.Admin.ThinProvision custom property with a value of True in the Blueprint. This should be done for all machines and disks in the blueprint. You can add the custom property at the component level or at the blueprint level, which is applied to all applicable components.
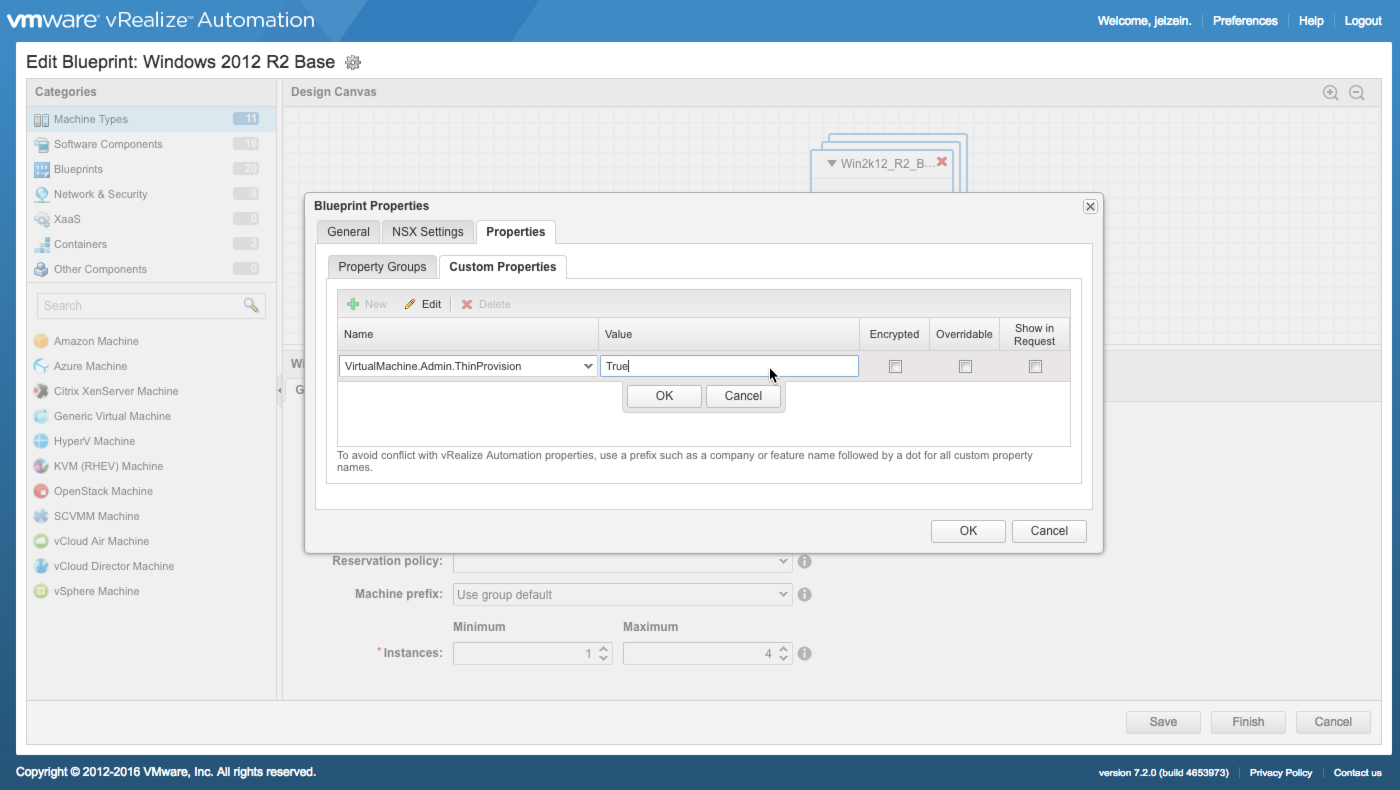
…that’s basically it.
Testing Things Out
Now that things are configured, let’s give it a test run. For starters, edit a blueprint and add a large disk if there isn’t one already there. Ensure the disks are thin provisioned. Here i’ve added a 1TB disk called “Data1” to the windows component.
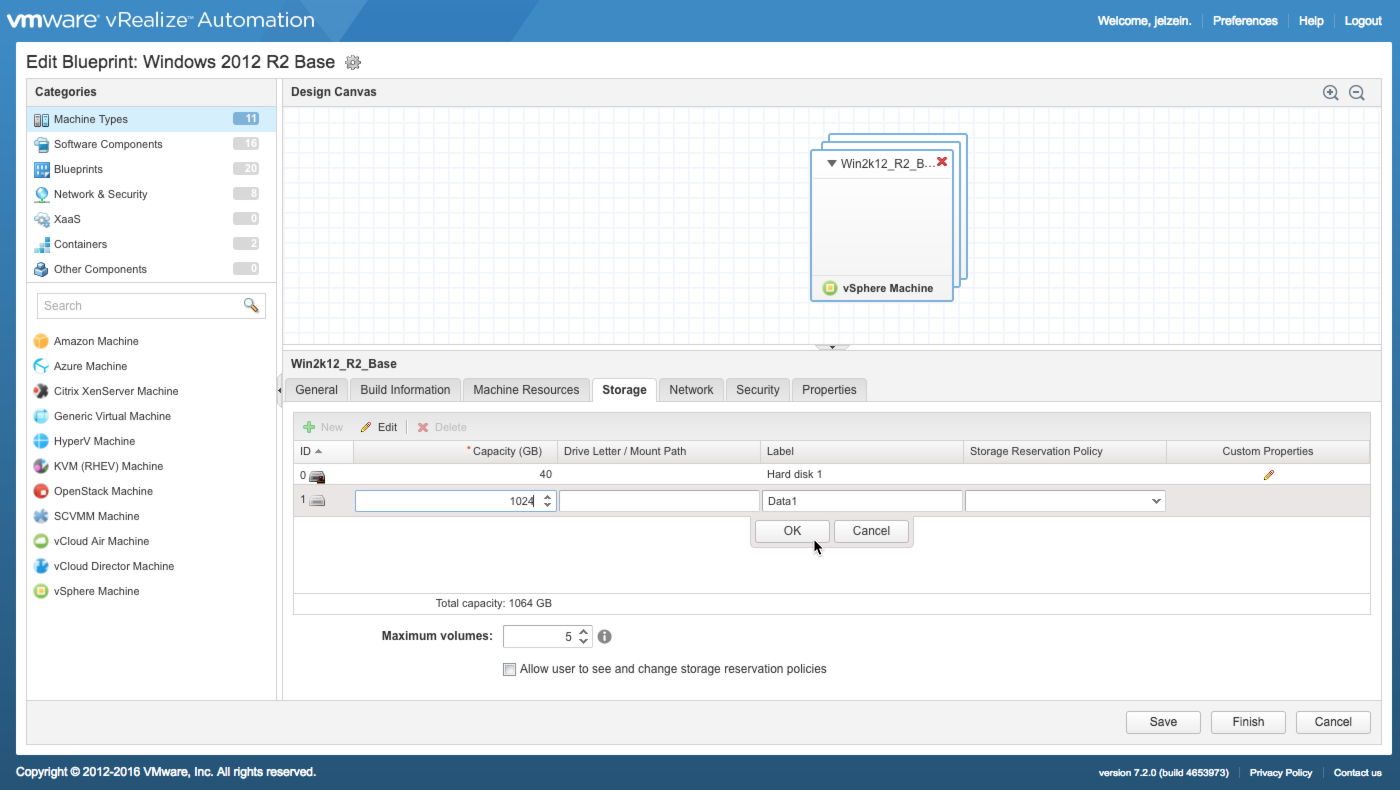 .
.
Once that is saved, go and request the blueprint from the catalog (this blueprint has already been published and entitled…prerequisites before you can request it).
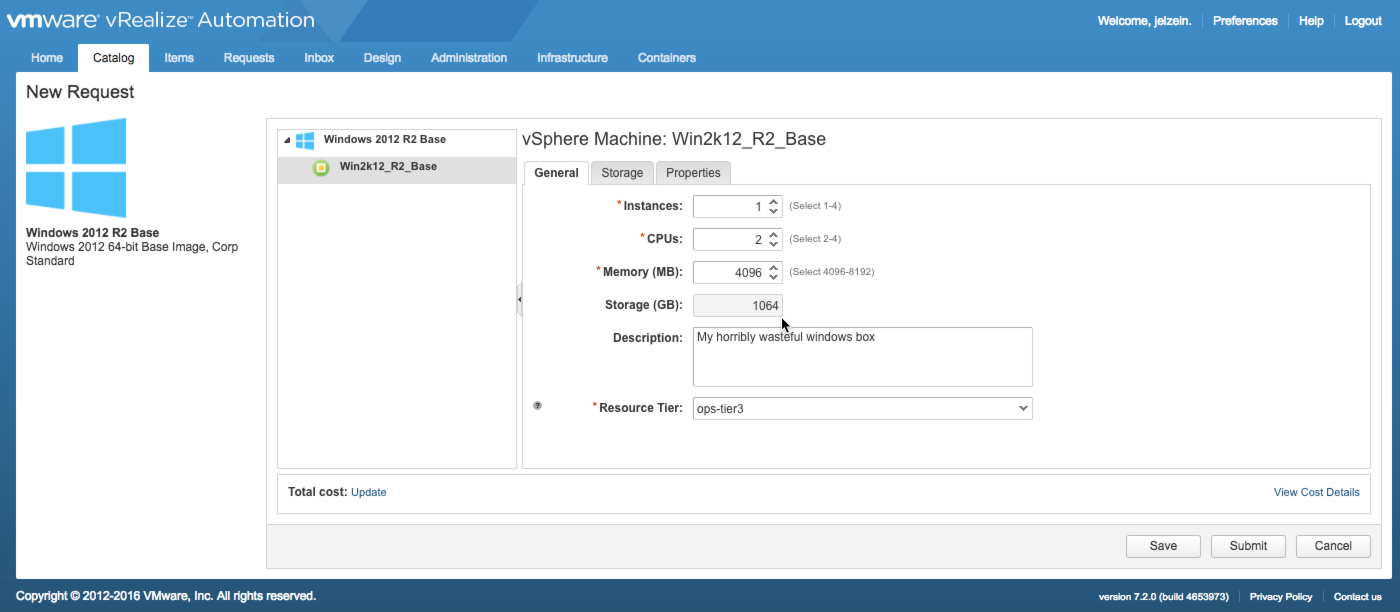
This blueprint on it’s own will require 1064GB once it’s requested. The total Free space of the storage path is 1495GB…so, based on my decision tree, this should work just fine. Once requested, you can view provisioning status in the Execution Information window. Here you can see the Allocation was successfully completed, followed by a successful provisioning and deliver of the machine.
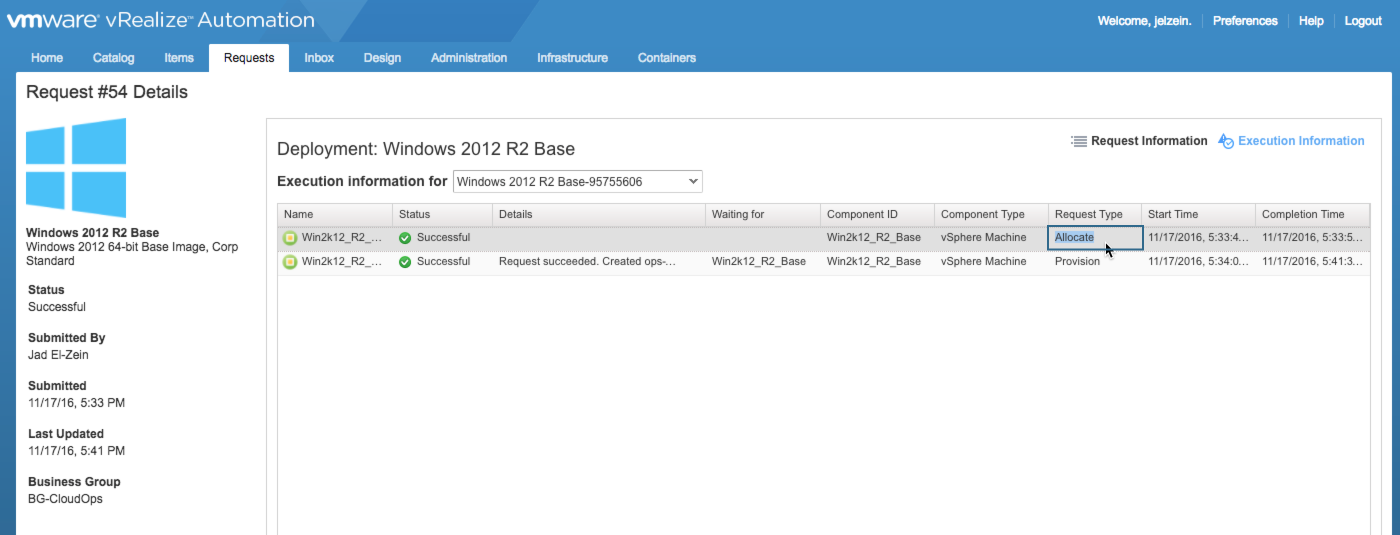
In an effort to fill my reserved capacity, i went ahead and deployed 2 additional copies of this same blueprint…both were successful. Back in the Reservation, I can see the storage allocations for the 3 machines under “This Reservation Allocated”…3192GB has been allocated at this point.
What’s interesting here is the “Free” number — while 3192GB has been allocated, almost no storage has been consumed from the physical storage path. That is because this machine was provisioned as Linked Clone…and the delta data is negligible. In vSphere, each of these VMs acurately show 1064GB allocated while only 11GB is in use by the OS. This also validates the the disks were thin provisioned. If these weren’t linked clones, I would have seen 33GB pulled from the Free pool (3 x 11GB).
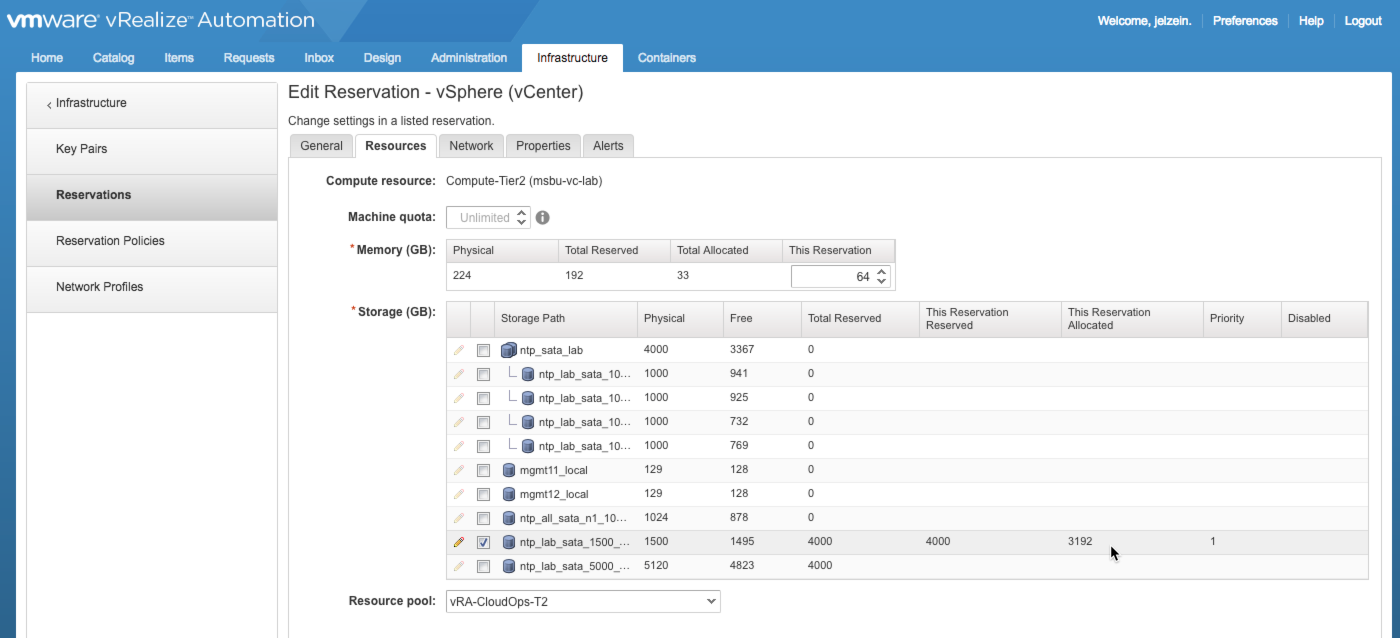
Let’s push things a little more. Now i find myself in a dilema…I still have tons of Free capacity in the storage path but I’m just about out of reserved capacity. I’ll try to request another one of my bloated Windows machines and see what happens…
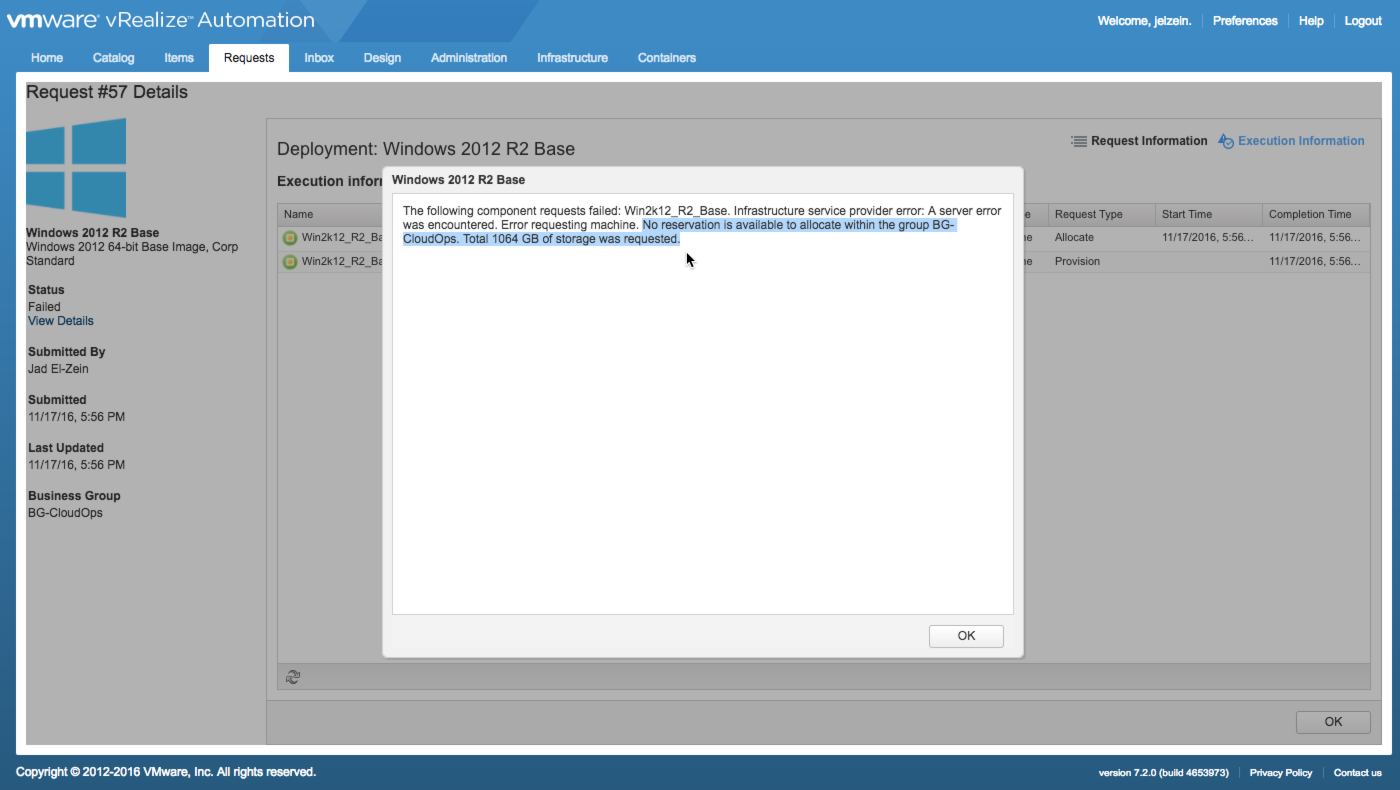
As I expected, the request failed within seconds since vRA was unable to allocate the 1064GB of storage to any available resources. But now that I know what my ratios look like, I can get much more aggressive by increasing the reserved capacity to something much higher.
I know what you’re thinking — the right thing to do is stop provisioning machines with bloated drives, but that’s besides the point!!!
+++++
virtualjad
1 Comment